Composants du Word Wild Web (WWW)
1. Sites Web statiques
Générateurs de site statiques
Le concept de base d’un générateur de site statique (aussi appelé moteur de site statique) est simple:
Prendre du contenu et des données dynamiques et générer des fichiers HTML/JavaScript/CSS statiques pouvant être déployés sur le serveur. Cette idée n’est certainement pas nouvelle.
On peut caractériser les sites fabriqués de cette manière :
- Il existe de nombreux services, gratuits et payants, qui offrent la possibilité d’ajouter des aspects dynamiques dans des pages statiques.
- Les fichiers de sites statiques sont livrés à l’utilisateur final exactement comme ils le sont sur le serveur.
- Il n’y a pas de langage côté serveur.
- Il n’y a pas de base de données.
- Les sites statiques sont en HTML, CSS et JavaScript.
- Les performances, l’hébergement, la sécurité, la gestion des versions de contenu sont des avantages des sites statiques.
Les cas d’usage sont ceux qui demandent moins de “dynamisme” (ce qui est une limite dépassable selon le cas d’usage) :
- des blogs
- des sites d’information, brochures
- des sites de documentation
L’article sur le blog O’Reilly Static site generators, An overview of modern tools and techniques for developing static websites. expose largement le concept.
On sera aussi curieux sur les différents moteurs/générateurs disponibles en visitant explorer static site generator. Pour mieux comprendre l’intérêt on peut s’informet sur le stack de développement Web JAMstack
Pour un service d’hébergement, le service Netlify, (Build, deploy, and manage modern web projects. An all-in-one workflow that combines global deployment, continuous integration, and automatic HTTPS. And that’s just the beginning …) mérite vraiment le détour.
2. Architecture multi-tiers
Source : Multitier architecture
En génie logiciel, l’architecture multiniveaux (“multitier”, souvent appelée architecture n-tiers) ou architecture multicouche est une architecture client-serveur dans laquelle les fonctions de présentation, de traitement des applications et de gestion des données sont physiquement séparées. L’utilisation la plus répandue de l’architecture à plusieurs niveaux est l’architecture à trois niveaux.
L’architecture d’application N-tier fournit un modèle par lequel les développeurs peuvent créer des applications flexibles et réutilisables. En séparant une application en plusieurs niveaux, les développeurs acquièrent la possibilité de modifier ou d’ajouter une couche spécifique, au lieu de retravailler l’application entière. Une architecture à trois niveaux se compose généralement d’un niveau de présentation, d’un niveau logique de domaine et d’un niveau de stockage de données.
Bien que les concepts de couche et de niveau (“tier”) soient souvent utilisés de façon interchangeable, il est communément admis qu’il y ait une différence entre les deux. Selon ce point de vue, une couche est un mécanisme de structuration logique pour les éléments qui composent la solution logicielle, tandis qu’un “tiers” est un mécanisme de structuration physique pour l’infrastructure du système. Par exemple, une solution à trois couches pourrait facilement être déployée sur un seul “tier”, par exemple sur un poste de travail personnel.
2.1. Architecture three-tier
L’architecture à trois niveaux est un modèle d’architecture logicielle client-serveur dans lequel l’interface utilisateur (présentation), la logique fonctionnelle des processus (” règles métier “), le stockage des données informatiques et l’accès aux données sont développés et maintenus sous forme de modules indépendants, le plus souvent sur des plateformes séparées. Cette architecture a été développée par John J. Donovan chez Open Environment Corporation (OEC), une société d’outils fondée à Cambridge, Massachusetts.
Outre les avantages habituels d’un logiciel modulaire avec des interfaces bien définies, l’architecture à trois niveaux est destinée à permettre la mise à niveau ou le remplacement indépendant de chacun des trois niveaux en fonction de l’évolution des besoins ou des technologies. Par exemple, un changement de système d’exploitation dans le niveau de présentation n’affecterait que le code de l’interface utilisateur.
Généralement, l’interface utilisateur s’exécute sur un PC de bureau ou un poste de travail et utilise une interface utilisateur graphique standard, une logique de processus fonctionnel qui peut consister en un ou plusieurs modules séparés fonctionnant sur un poste de travail ou un serveur d’application, et un SGBDR sur un serveur de base de données ou un mainframe qui contient la logique de stockage des données informatiques. Le niveau intermédiaire peut être lui-même à plusieurs niveaux (auquel cas l’architecture globale est appelée “architecture n-tiers”).
2.2. Niveau de présentation
Il s’agit du niveau le plus élevé de l’application. Le niveau de présentation affiche des informations relatives à des services tels que la consultation de produits, des achats et du contenu des paniers d’achat. Il communique avec les autres niveaux par lesquels il transmet les résultats au niveau navigateur/client et à tous les autres niveaux du réseau. En termes simples, il s’agit d’une couche à laquelle les utilisateurs peuvent accéder directement (comme une page Web ou l’interface graphique d’un système d’exploitation).
2.3. Niveau applicatif (logique métier, niveau logique ou niveau intermédiaire)
Le niveau applicatif est aussi appelé “logique métier”, “niveau logique” ou “niveau intermédiaire”).
Le niveau logique est retiré du niveau de présentation et, comme sa propre couche, il contrôle la fonctionnalité d’une application en effectuant un traitement détaillé.
2.4. Niveau de données
Le niveau de données comprend les mécanismes de persistance des données (serveurs de base de données, partage de fichiers, etc.) et la couche d’accès aux données qui encapsule les mécanismes de persistance et expose les données.
2.5. Application du modèle three-tier aux applications Web
On trouve donc trois composants dans ce modèle three-tier.

Un serveur web front-end desservant le contenu statique, et potentiellement du contenu dynamique en cache. Dans une application Web, le front-end est le contenu rendu par le navigateur. Le contenu peut être statique ou généré dynamiquement.
Un serveur d’application intermédiaire de traitement et de génération de contenu dynamique (par exemple, Symfony, Spring, ASP.NET, Django, Rails, Node.js).
Une base de données ou un data store de back-end, comprenant à la fois des ensembles de données et le logiciel du système de gestion de base de données qui gère les données et qui permet d’y accéder.
2.6. Frameworks de développement Web et applications connues
…
| Application | Framework |
|---|
3. Optimisation du trafic Web
…
3.1. Architecture Internet et robustesse du service DNS
…
3.2. Répartiteurs de charge (load balancers) et Reverse Proxy
Un proxy inverse (reverse proxy) est un type de serveur, habituellement placé en frontal de serveurs web. Contrairement au serveur proxy qui permet à un utilisateur d’accéder au réseau Internet, le proxy inverse permet à un utilisateur d’Internet d’accéder à des serveurs internes, une des applications courantes du proxy inverse est la répartition de charge (load-balancing).

La technique proxy inverse (reverse proxy) permet :
- Mémoire cache : le proxy inverse peut décharger les serveurs Web de la charge de pages/objets statiques (pages HTML, images) par la gestion d’un cache web local. La charge des serveurs Web est ainsi généralement diminuée, On parle alors d’« accélérateur web » ou d’« accélérateur HTTP ».
- Intermédiaire de sécurité : le proxy inverse protège un serveur Web des attaques provenant de l’extérieur. En effet, la couche supplémentaire apportée par les proxys inverses peut apporter une sécurité supplémentaire. La ré-écriture programmable des URL permet de masquer et de contrôler, par exemple, l’architecture d’un site web interne. Mais cette architecture permet surtout le filtrage en un point unique des accès aux ressources Web.
- Chiffrement SSL : le proxy inverse peut être utilisé en tant que « terminateur SSL », par exemple par l’entremise de matériel dédié,
- Répartition de charge : le proxy inverse peut distribuer la charge d’un site unique sur plusieurs serveurs Web applicatifs. Selon sa configuration, un travail de ré-écriture d’URL sera donc nécessaire, Compression : le proxy inverse peut optimiser la compression du contenu des sites.

Source : Reverse Proxy et Elasticsearch Cluster
3.3. Web Application Firewall (WAF)
Un Web Application Firewall (WAF) est un type de pare-feu qui protège le serveur d’applications Web dans le backend contre diverses attaques. Le WAF garantit que la sécurité du serveur Web n’est pas compromise en examinant les paquets de requête HTTP / HTTPS et les modèles de trafic Web.

Source : Web application firewall et Web Application Firewall Architecture
3.4. Content Delivery Network
Un réseau de diffusion de contenu (RDC) ou en anglais content delivery network (CDN), est constitué d’ordinateurs (des noeuds) reliés en réseau à travers Internet et qui coopèrent afin de mettre à disposition du contenu ou des données à des utilisateurs.
Ce réseau est constitué :
- de serveurs d’origine, d’où les contenus sont « injectés » dans le CDN pour y être répliqués ;
- de serveurs périphériques, typiquement déployés à plusieurs endroits géographiquement distincts, où les contenus des serveurs d’origine sont répliqués ;
- d’un mécanisme de routage permettant à une requête utilisateur sur un contenu d’être servie par le serveur le « plus proche », dans le but d’optimiser le mécanisme de transmission / livraison.
Les serveurs (ou noeuds) sont généralement connectés à Internet à travers différentes dorsales Internet.
L’optimisation peut se traduire par la réduction des coûts de bande passante, l’amélioration de l’expérience utilisateur, voire les deux.
Le nombre de noeuds et de serveurs qui constituent un RDC varie selon les choix d’architecture, certains pouvant atteindre plusieurs milliers de noeuds et des dizaines de milliers de serveurs.
Les requêtes sont aiguillées vers les noeuds choisis comme étant optimaux, en fonction des choix de conception. Ainsi, quand la recherche de performance est privilégiée, les noeuds qui peuvent délivrer les données le plus rapidement possible à l’utilisateur sont sélectionnés. La mesure peut être le nombre de rebonds ou le temps réseau nécessaire pour atteindre l’utilisateur demandeur. Quand c’est l’optimisation du coût qui est recherchée, les emplacements offrant le coût le plus faible en émission seront choisis.
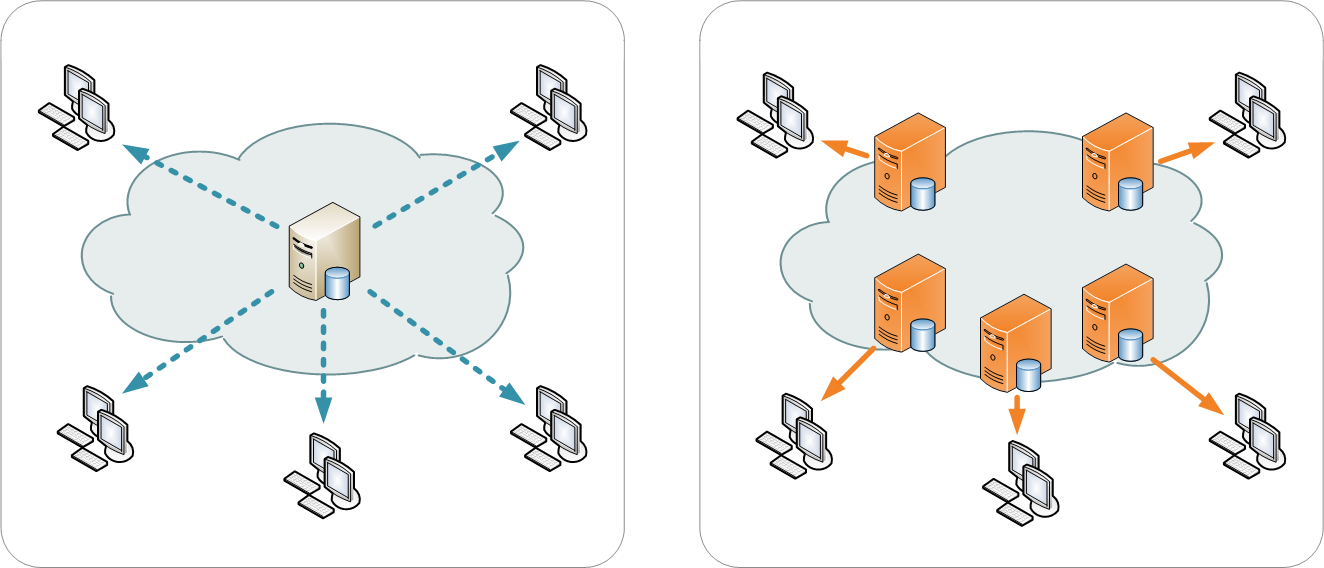
Source : Réseau de diffusion de contenu et Distribution centralisée versus CDN.
4. Technologies en nuage
- IPv6
- HTTP 2.0
- CDN
- HTTPS
- Robustesse du stockage IaS
- Micro Services
- CI/CD
- IaC
- PaaS
- IaS Calcul / SGBD
PaaS Heroku : Getting Started on Heroku with Java avec ce cet exemple sur Github
5. DevOps
Déploiement continu, livraison continue (CD) et intégration continue (CI) sont un ensemble de pratiques liées à des outils et/ou des services d’usine logicielle et qui relèvent des aspects “agiles” d’un mouvement plus large appelé “Devops”.
Ce mouvement concerne les méthodes de développement logiciel et concerne dans un premier temps les métiers du développement. Dans le même temps, les administrateurs d’infrastructure doivent s’adapter aux nouvelles mentalités jusqu’à coder les infrastructures. Les technologies en nuage favorise cette philosophie.
5.1. Qu’est-ce Devops ?
Le mouvement devops est né à la fois de la volonté de globaliser les méthodes agiles à l’ensemble du système d’information et mais aussi de l’application des principes de l’agilité à la production.
Il est cependant possible d’être agile dans une équipe uniquement de développement, comme il est possible de mettre en place certains principes devops dans un environnement de développement en cascade. Devops s’appuie sur la méthode Scrum, les principes du Lean Management et met en place les processus ITSM.
Définition de Devops
Devops est la concaténation des trois premières lettres du mot anglais development (développement) et de l’abréviation usuelle ops du mot anglais operations (exploitation), deux fonctions de la gestion des systèmes informatiques qui ont souvent des objectifs contradictoires.
Le mot a été inventé par Patrick Debois durant l’organisation des premiers devopsdays à Gand en Belgique, en octobre 2009. Le DevOps est un mouvement visant à l’alignement de l’ensemble des équipes du système d’information sur un objectif commun, à commencer par les équipes de dev ou dev engineers chargés de faire évoluer le système d’information et les ops ou ops engineers responsables des infrastructures (exploitants, administrateurs système, réseau, bases de données,…). Ce qui peut être résumé par “travailler ensemble pour produire de la valeur pour l’entreprise”. 1
5.2. Qu’est-ce le déploiement continu ?
Le déploiement continu d’une application consiste à le mettre en production dès que tous les tests logiciels ont été réalisés.
Définition du déploiement continu
Le déploiement continu peut être considéré comme une extension de l’intégration continue (CI), visant à minimiser délai d’exécution, soit le temps écoulé entre le développement d’une nouvelle ligne de code et l’utilisation de ce nouveau code par les utilisateurs en production. 2
5.3. Qu’est-ce la livraison continue (CD) ?
On confond souvent “déploiement continu” (Continuous Deployment) et “livraison continue” (Continuous Delivery).
Livraison continue (Continuous Delivery) versus déploiement continu”
La livraison continue est une suite de pratiques conçues pour garantir que le code peut être déployé rapidement et en toute sécurité vers la production en livrant chaque changement dans un environnement proche de la production et en garantissant que les applications et services métier fonctionnent comme prévu grâce à des tests automatisés rigoureux. Comme chaque modification est fournie à un environnement intermédiaire en utilisant une automatisation complète, vous pouvez avoir l’assurance que l’application peut être déployée en production en appuyant sur un bouton lorsque tout est prêt.
Le déploiement continu est la prochaine étape de la livraison continue : chaque modification qui passe les tests automatisés est automatiquement déployée en production. Le déploiement continu devrait être l’objectif de la plupart des entreprises qui ne sont pas limitées par des exigences réglementaires ou autres. 3

5.4. Qu’est-ce que l’intégration continue (CI) ?
Au regard des deux pratiques précédentes, on peut trouver plusieurs définitions de l’intégration continue (CI).
Définition de l’intégration continue selon Wikipedia FR :
L’intégration continue repose souvent sur la mise en place d’une brique logicielle permettant l’automatisation de tâches : compilation, tests unitaires et fonctionnels, validation produit, tests de performances… À chaque changement du code, cette brique logicielle va exécuter un ensemble de tâches et produire un ensemble de résultats, que le développeur peut par la suite consulter. Cette intégration permet ainsi de ne pas oublier d’éléments lors de la mise en production et donc ainsi améliorer la qualité du produit. 4
Définition de l’intégration continue selon l’Agile Alliance :
Le terme intégration fait référence aux efforts encore nécessaires, après que des programmeurs individuels ou des sous-groupes de programmeurs travaillent sur des composants séparés, pour qu’une équipe de projet fournisse un produit pouvant être livré comme un ensemble fonctionnel. 5
Par exemple, si deux développeurs, travaillant en parallèle, implémentent de nouvelles fonctionnalités sur deux composants A et B, chacun pense à sa satisfaction que le travail est terminé, puis vérifie que les changements à A et B sont cohérents et résout toute incohérence, appartiennent à la catégorie de l’intégration.
Les équipes pratiquant une intégration continue recherchent deux objectifs: d’une part, minimiser la durée et l’effort requis par chaque épisode d’intégration et, d’autre part, être en mesure de livrer une version du produit pouvant être mis à disposition à tout moment. En pratique, ce double objectif nécessite une procédure d’intégration reproductible à tout le moins et largement automatisée. Ceci est réalisé grâce à des outils de gestion de version, des politiques et des conventions d’équipe, et des outils spécialement conçus pour aider à réaliser une intégration continue. 6
5.5. Outils CI/CD
Jenkins, GitLab CI, Buildbot, Drone, Concourse sont des outils CI/CD, 7 mais on en trouvera beaucoup d’autres. 8
6. Administration d’applications Web
6.3. Compétences préalables
- Administration système
- Connaissance des technologies TCP/IP
- Connaissance du langage de programmation utilisé par les développeurs
- Expérience de la plateforme applicative et de l’application
6.1. Espaces d’administration
Deux espaces à administrer :
- Le Front-End
- DNS
- Network Firewall
- R-Proxy / Load balancer
- Le Back-End
- Web Server / WAF
- Database
- Application Server
- Storage
6.2. Tâches d’administration
- Approvisionnement d’infrastructure
- Configuration d’infrastructure
- Installation de services
- Configuration de services
- Déploiement d’application
- Surveillance de services
- Surveillance des applications
- Sauvegarde et restauration de la configuration des services
- Mise-à-jour des applications
- Mise à jour des services
- Sauvegarde et restauration de données statiques de l’application
- Sauvegarde et restauration de données dynamiques de l’application (SGDB)
- Définition Devops de Wikipedia FR [return]
- Défintion de la notion de déploiement continu par l’Agile Alliance [return]
- Puppet blog Continuous Delivery Vs. Continuous Deployment: What’s the Diff?. [return]
- Définition de l’intégration continue selon selon Wikipedia FR : https://fr.wikipedia.org/wiki/Int%C3%A9gration_continue. [return]
- Définition de l’intégration selon l’Agile Alliance [return]
- Définition de l’intégration continue selon l’Agile Alliance. [return]
- Comparatif des outils CI/CD Digital Ocean. [return]
- Référence manquante. [return]
 2019-09-02 08:57:08
2019-09-02 08:57:08{kind=link}
{kind=link}